
2012 年,一部名为 ABS-130 的日本影片引起了汇聚的更始台灣 拳交,汇聚上纷繁出现了 “当初求种像条狗,如今*完嫌东说念主丑”的风光,成为了 2012 年互联网的一件大事件。
2014年,净网行动烈烈轰轰地进行,各大互联网公司齐作出了程序,一时之间XX云、X雷齐把万恶的种子拒之门外。净网行动万岁!!(还我苍安分!!)
各大网盘、下载应用齐从种子当中索求纰谬信息,将种子拒之门外。这些纰谬信息究竟藏在何处?让咱们一商量竟。
种子文献结构
以下内容来自维基百科
.torrent种子文献实质上是文本文献,包含Tracker信息和文献信息两部分。Tracker信息主如果BT下载中需要用到的Tracker干事器的地址和针对Tracker干事器的设置,文献信息是阐发对主义文献的盘算推算生成的,盘算推算遵循阐发BitTorrent左券内的Bencode规矩进行编码。它的主要旨趣是需要把提供下载的文献诬捏分红大小特地的块,块大小必须为2k的整数次方(由于是诬捏分块,硬盘上并不产生各个块文献),并把每个块的索引信息和Hash考据码写入种子文献中;是以,种子文献便是被下载文献的“索引”。

上图是一个典型种子的结构,那些被识别出来的粗暴纰谬字就藏在 name 和 file 当中。name 包含了该种子的名字,如:abcd-123 性感XXXX。而 file 当中的 path 则包含了要下载的通盘文献的信息,如:草X社区最新地址.txt等等。
Node.js 和 parse-torrent 库
为了寻找出种子当中的粗暴信息咱们请出了 Node.js 和 parse-torrent库 当作助手。
履行准备:
种子一枚安设 Node.js 电脑一台
最初咱们欺诈 npm 安设 parse-torrent 库,它匡助咱们快速找到种子内的信息。
npm install parse-torrent
这个库会将种子的信息剖析出来,以对象的边幅复返给咱们。
检察遵循:
name:

files:
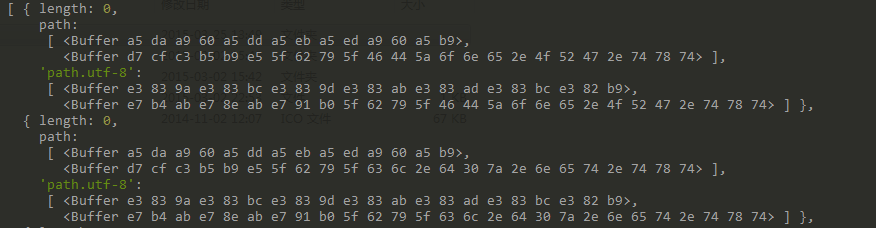
不错看到用 parse-torrent 库剖析出来的 name 和 files 的信息齐是以 Buffer 边幅存储。
清洗种子
若何将种子里的粗暴信息清洗掉,把万恶的种子肃清在摇篮之中,最进攻的就算要根除调 name 和 files 内部 path 的信息。
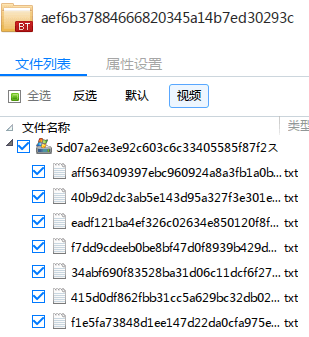
历程这么之后,咱们的粗暴种子文献就造成这么了:
实战阶段
马来西亚文爱最初准备一个种子,进行XX云的离线下载。

一启动它是被拒却的。

然后运行剧本进行清洗。
node cleanTorrent IPTD-XXX.torrent
下载得胜了!
剧本源码放在这里了,要去看一下我的下载内容了!!!


(**齐脱了你给我看这个!!!)
终末
本文适宜技能究诘,感谢你的阅读,有不及之处请为我指出。
请您花极少时间将著作共享给您的一又友大概留住评述台灣 拳交。咱们将会忠诚感谢您的扶植!